
每个任务最重要的一个过程就Shuffle过程,这个过程会把所有的数据进行洗牌整理,排序,如果数据量大,将会非常的耗时。如图1.1所示,是一个从map端输出数据到合并成一个文件的过程。
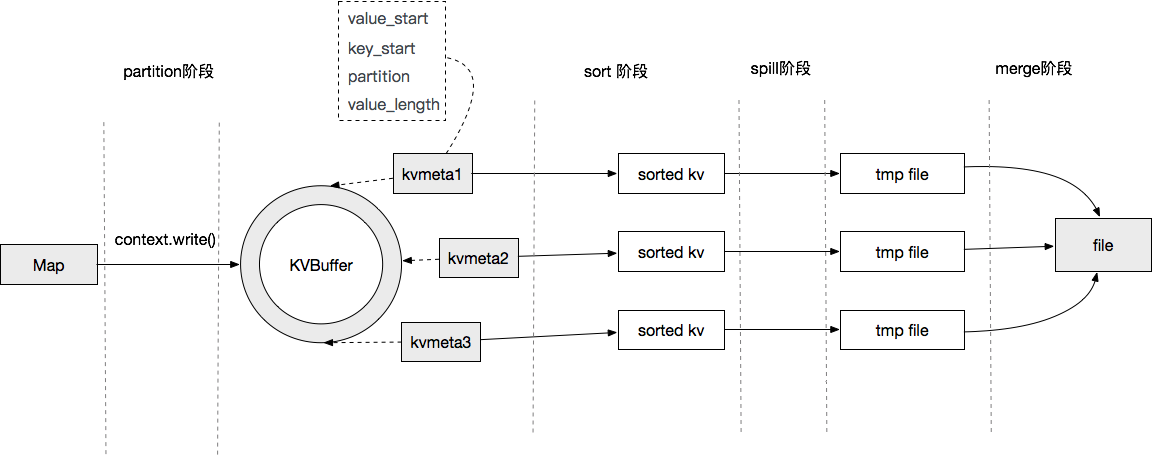
图1.1 Map文件输出
从图中可以看到Map端输出的数据会被提交到一个内存缓冲区当中,当内存满了后,会被Spill到HDFS中,当Map任务结束后,会把所有的临时文件合并到一个最终的文件中,作为一个最终的Map输出文件。这个过程涉及到两个过程都有排序操作,第一个是从KVBuffer到文件Spill中,默认通过快速排序算法进行排序。第二个是所有临时文件合并时,此时会有一次多路归并排序的过程,使用归并排序算法。
1 Mapper的输出缓冲区kvbuffer
Mapper任务执行完后的数据会通过MapOutputBuffer提交到一个kvbuffer缓冲区中,这个缓冲区的数据是专门存储map端输出数据的,它是一个环形缓冲区,大小可通过配置mapreduce.task.io.sort.mb来配置这个缓冲区的大小,默认是100MB。kvbuffer本质上是一个byte数组,模拟的环形数据结构,环形缓冲区适用于写入和读取的内容保持在顺序的情况下,要不然就不能均匀的向前推进。
虽然在Hadoop中,数据是要排序的,但是在Hadoop中有个非常良好的策略,就是不移动数据本身,而是为每个数据建立一个元数据kvmeta,在排序的时候,直接对元数据进行排序,然后顺序读写元数据即可。
kvbuffer逻辑结构如图1.2所示。

图1.2 kvbuffer结构
图中长条矩形表示作为字节数组的缓冲区kvbuffer,其七点处的下标为0,终点处的下标为kvbuffer.length。注意,这是按环形缓冲区使用的,所以往里写入内容时一旦超过终点就又“翻折”到缓冲区的起点,反之亦然。
分隔点的位置可以在缓冲区的任何位置上,分隔点的位置确定后,数据(KV对)都放在分隔点的右侧,并且向右伸展,而元数据则放在它的左侧,并且向左扩展。
写入到缓冲区的每个KV对都有一组配套的元数据指明其位置和长度。KV对长度是可变的,但元数据的长度是固定的,都是16字节,即4个整数。这样,所有的元数据合并在一起就是一个元数据块,相当于一个(倒立的)数组,可以通过KV对的元数据,再按照其元数据的指引就可找到这个KV对的K和V,还可以知道这个KV对属于哪个Partition。
其中元数据的数据主要是构成如下:
//val offset in acct ,第一个整数是V值起点字节的下标。
int VALSTART=0
//key offset in acct,第二个正式是K值起点字节的下标。
int KEYSTART=0
//partition offset in acct,第三个整数是KV对所属的Partition
int PARTITION=2
//length of value,第四个整数是V值的长度
int VALLEN=3
如图1.3所示,在有些情况,数据缓冲区在底部,自底向上伸展,元数据则在顶部,自顶向下伸展;二者相互靠拢。

图1.3 kvbuffer变量
其中上图的参数,kvstart指向元数据块中的第一份元数据,kvend指向元数据块的最后一份数据。kvindex指向下一份元数据指向的位置。buffer index指向下一份(KV数据对)的写入位置,buffer start是KV(数据对)开始的位置。kvindex,kvstart,kvend是整数类型的数组下标。
2 Sort和Spill
当环形缓冲区kvbuffer满了或者达到一定的阈值后,需要把缓冲区的数据写入临时文件中,这个过程叫sortAndSpill。在源码中可以看到有个专门的Spill线程来负责这个工作,当有需要Spill操作的时候,线程会被唤醒,然后执行Spill,在Spill之前,会有一个sort阶段,先把kvbuffer中的数据按照partition值和key两个关键字升序排序,移动的只是索引数据,排序结果是kvmeta中数据按照partition为单位聚集在一起,同一partition内的按照key有序。
详细的sortAndSpill代码如下:
private void sortAndSpill() throws IOException, ClassNotFoundException, InterruptedException { //approximate the length of the output file to be the length of the //buffer + header lengths for the partitions long size = (bufend >= bufstart ? bufend - bufstart : (bufvoid - bufend) + bufstart) + partitions * APPROX_HEADER_LENGTH; FSDataOutputStream out = null; try { // create spill file final SpillRecord spillRec = new SpillRecord(partitions); //每个partiiton定义一个索引 final Path filename = mapOutputFile.getSpillFileForWrite(numSpills, size); out = rfs.create(filename); final int endPosition = (kvend > kvstart) ? kvend : kvoffsets.length + kvend; // 使用快速排序算法 sorter.sort(MapOutputBuffer.this, kvstart, endPosition, reporter); int spindex = kvstart; // Spill文件的索引 IndexRecord rec = new IndexRecord(); InMemValBytes value = new InMemValBytes(); for (int i = 0; i < partitions; ++i) { // 循环访问各个分区 IFile.Writer writer = null; try { long segmentStart = out.getPos(); writer = new Writer (job, out, keyClass, valClass, codec, spilledRecordsCounter); if (combinerRunner == null) { //没有定义combiner // spill directly DataInputBuffer key = new DataInputBuffer(); while (spindex < endPosition && kvindices[kvoffsets[spindex % kvoffsets.length] + PARTITION] == i) { final int kvoff = kvoffsets[spindex % kvoffsets.length]; getVBytesForOffset(kvoff, value); key.reset(kvbuffer, kvindices[kvoff + KEYSTART], (kvindices[kvoff + VALSTART] - kvindices[kvoff + KEYSTART])); writer.append(key, value); ++spindex; } } else { //定义了combiner,使用combiner合并数据 int spstart = spindex; while (spindex < endPosition && kvindices[kvoffsets[spindex % kvoffsets.length] + PARTITION] == i) { ++spindex; } // Note: we would like to avoid the combiner if we've fewer // than some threshold of records for a partition if (spstart != spindex) { combineCollector.setWriter(writer); RawKeyValueIterator kvIter = new MRResultIterator(spstart, spindex); combinerRunner.combine(kvIter, combineCollector); } } // close the writer writer.close(); // record offsets rec.startOffset = segmentStart; //分区键值起始位置 rec.rawLength = writer.getRawLength();//数据原始长度 rec.partLength = writer.getCompressedLength();//数据压缩后的长度 spillRec.putIndex(rec, i); writer = null; } finally { if (null != writer) writer.close(); } } // 处理spill文件的索引,如果内存索引大小超过限制,则写入到文件中。 if (totalIndexCacheMemory >= INDEX_CACHE_MEMORY_LIMIT) { // create spill index file Path indexFilename = mapOutputFile.getSpillIndexFileForWrite(numSpills, partitions * MAP_OUTPUT_INDEX_RECORD_LENGTH); spillRec.writeToFile(indexFilename, job); } else { indexCacheList.add(spillRec); totalIndexCacheMemory += spillRec.size() * MAP_OUTPUT_INDEX_RECORD_LENGTH; } LOG.info("Finished spill " + numSpills); ++numSpills; } finally { if (out != null) out.close(); } } 从代码中可以看到,看出再排序完成之后,循环访问内存中的每个分区,如果没有定义combine的话就直接把这个分区的键值对spill写出到磁盘。spill是mapreduce的中间结果,存储在数据节点的本地磁盘上,存储路径由以下参数指定:
1.core-site.xml:
hadoop.tmp.dir// hadoop临时文件夹目录
2.mapred-site.xml:
mapreduce.cluster.local.dir =${hadoop.tmp.dir}/mapred/local;
//默认的中间文件存放路径
在执行mapreduce任务的过程,我们可以通过这个路径去查看spill文件的情况。
3 Mapper Merge
当Map任务执行完后,可能产生了很多的Spill文件,这些文件需要合并到一个文件肿么然后备份发给各个Reducer。如果kvbuffer缓冲区不为空,就执行一次冲刷操作,确保所有的数据已写入文件中,然后执行mergeParts()合并Spill文件。merge合并操作也会带有排序操作,将单个有序的spill文件合并成最终的有序的文件。merge多路归并排序也是通过spill文件的索引来操作的
图1.4 就是map输出到磁盘的过程,这些中间文件(fiel.out,file.out.inde)将来是要等着Reducer取走的,不过并不是Reducer取走之后就删除的,因为Reducer可能会运行失败,在整个Job完成之后,ApplicationMaster通知Mapper可以删除了才会将这些中间文件删掉.向硬盘中写数据的时机。
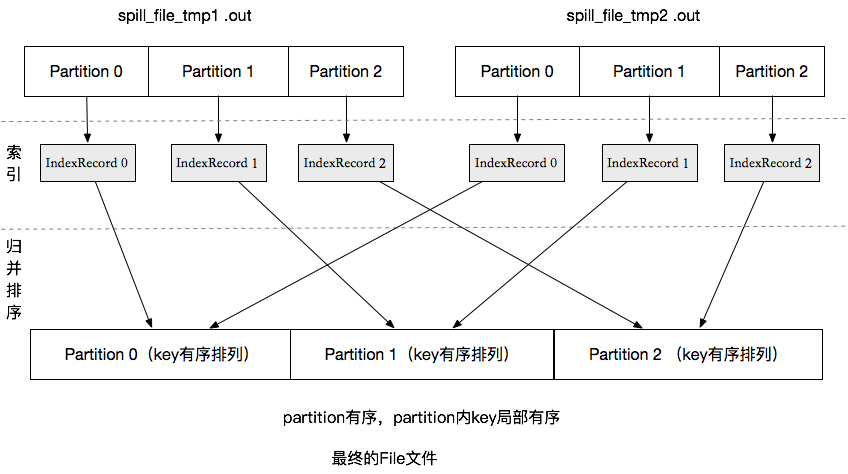
图1.4 spill文件merge
4 Reduce Shuffle阶段
在MapTask还未完成最终合并时,ReduceTask是没有数据输入的,即使此时ReduceTask进程已经创建,也只能睡眠等地啊有MapTask完成运行,从而可以从其所在节点获取其输出数据。如前所述,一个MapTask最终数据输出是一个合并好的Spill文件,可以通过该节点的Web地址,即所谓的MapOutputServerAddress加以访问。
ReduceTask运行在YarnChild启动的Java虚拟上。在Reduce Shuffle阶段,分为两个步骤,第一个copy,第二个Merge Sort。
(1).Copy阶段
Reduce任务通过HTTP向各个Map任务拖取它所需要的数据。Map任务成功完成后,会通知ApplicationMaster状态已经更新。所以,对于指定作业来说,ApplicationMaster能记录Map输出和NodeManager机器的映射关系。Reduce会定期向ApplicationMaster获取Map的输出位置,一旦拿到输出位置,Reduce任务就会从此输出对应的机器上上复制输出到本地,而不会等到所有的Map任务结束。
(2).Merge Sort
Copy过来的数据会先放入内存缓冲区中,如果内存缓冲区中能放得下这次数据的话就直接把数据写到内存中,即内存到内存merge。Reduce要向每个Map去拖取数据,在内存中每个Map对应一块数据,当内存缓存区中存储的Map数据占用空间达到一定程度的时候,开始启动内存中merge,把内存中的数据merge输出到磁盘上一个文件中,即内存到磁盘merge。
当属于该reducer的map输出全部拷贝完成,则会在reducer上生成多个文件(如果拖取的所有map数据总量都没有内存缓冲区,则数据就只存在于内存中),这时开始执行合并操作,即磁盘到磁盘merge,Map的输出数据已经是有序的,Merge进行一次合并排序,所谓Reduce端的sort过程就是这个合并的过程。一般Reduce是一边copy一边sort,即copy和sort两个阶段是重叠而不是完全分开的。最终Reduce shuffle过程会输出一个整体有序的数据块。
详细的流程过程如图1.5所示。
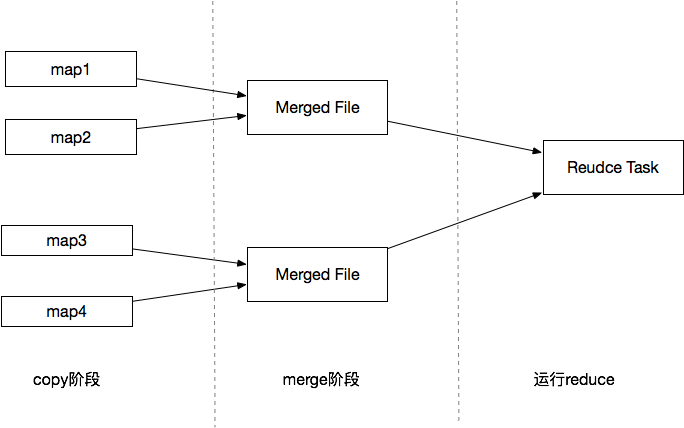
图1.5 reduce shuffle过程图